前言
系统全流程压测过程中,发现某一服务实例CPU占用打到85%,高峰时可能触发容器告警,影响系统稳定。但是该服务已经在前期做了几期优化,例如数据批量更新、使用本地缓存、异步线程处理等方式。但是只要开启整个订单的全流程处理,就会出现实例CPU飙升。对此需要进行进一步的分析和优化
线程分析
容器CPU占用高,一般是数据处理耗时长、资源的大量读写、频繁的GC、大量的运算等场景。针对于此,在进行压测的过程中,需要实时分析容器中线程的CPU占用情况。一般可以通过Linux自带top命令,或者通过Arthas工具来获取。
通过Arthas的dashboard命令,能定时获得类似top命令的结果,从而可以很方便地观察实例当前线程CPU占用、GC情况。其中实例的线程CPU占用主要情况如下:
logback线程CPU占用在50~70%间波动 ,且有2条左右线程并行处理
Kafka的一些consumer-task线程CPU占用在40~70%间波动,且有多个Topic,每个Topic有5条线程并行处理
线程池线程占CPU占用在15~30%间波动,且有10条左右线程并行处理
针对第1点,正常的日志输出不应该有这么高的占用,于是排查了一下实例的日志配置。发现压测环境的容器配置的DEBUG级别的日志,这个级别在压测场景中会导致大量日志的输出,确认该级别是误配之后,将其改INFO 级别后logback线程CPU占用稳定在20%左右,基本正常
针对第2点,系统架构针对分布式事务采用的是本地消息表的形式实现的,跨服务间的异步事务都通过Kafka信息的发送和处理来保证最终消息的一致性。在大量订单被处理的时候,会有很多异步的消息接收和处理,确实会导致很高的CPU占用。且具体的业务处理中流程较多,事务较大,涉及到大量的DB操作,该部分经过多次优化已经很难再有很明显的提升
针对第3点,线程池会处理系统中的一些兜底逻辑,同时一些涉及上下游系统的数据也会通过线程池来进行异步处理,且该部分线程CPU占用属于可接受范围内
综上整体看起来仅通过线程分析无法进一步定位到CPU占用高的具体细节,这时候就需要借助Arthas提供的采样分析命令profiler来进一步定位异常了
火焰图生成和使用
profiler start #开始采样
profiler stop #停止采样
profiler start -d 300 #自动采样300秒后停止采样完成后,会在arthas控制台打印采样文件存放的路径。默认的采样行为是将采样周期内所有方法在所有线程的CPU执行情况进行统计,默认输出一个html格式的火焰图,如下所示:
async-profiler生成的火焰图文件,其中绿色是用户方法调用,红色是内核调用,黄色是JVM调用。其支持以下操作:
将火焰图翻转
通过方法、类名、正则表达式来匹配搜索符合条件的方法,并通过紫色标示,以便于分析,通过ESC可以取消筛选
根据当前选择的方法信息,展示相关的方法占整体的比例,一般在右上角以百分比的形式展示
鼠标放在对应的方法上时,可以展示在采样周期内该方法执行了多少次,以及消耗的CPU百分比
选中某个方法时,会将该方法作为CPU周期统计的基准(即100%),并展示该方法进一步调用的其他方法在该方法内消耗的CPU百分比,同时搜索也将只针对于该基准方法的后续方法
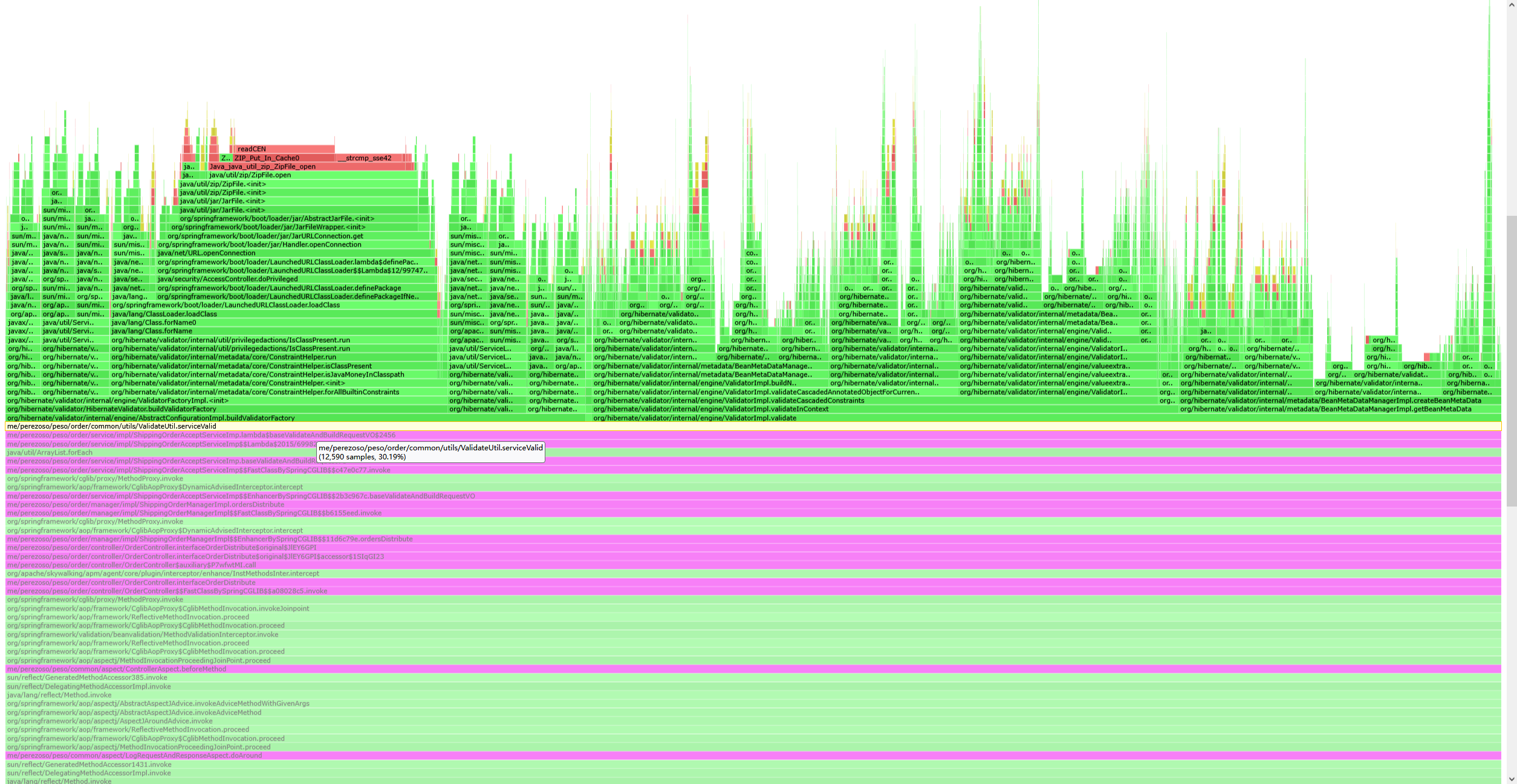
上图展示了搜索(紫色标识)、指定方法层级(点击serviceValid方法)、鼠标悬浮(展示CPU占用的信息)
火焰图分析
一般而言,用户方法调用的绿色方法越宽,越高则说明该方法消耗的CPU资源越多,则该方法需要重点关注
可以通过灵活的使用搜索功能,来整体分析某个方法在采样周期的总CPU消耗
在后续的分析过程中,主要发现了下面几个CPU占用异常的场景
ValidatorFactory重复创建
public static void serviceValid(Object object) {
String validMessage = "";
try {
//初始化检查器。
ValidatorFactory validatorFactory = Validation.byProvider(HibernateValidator.class)
.configure().failFast(false).buildValidatorFactory(); //(1)
Validator validator = validatorFactory.getValidator();
//检查object
Set<ConstraintViolation<Object>> set = validator.validate(object); //(2)
Set<ConstraintViolation<Object>> set = VALIDATOR.validate(object); //(4)
//循环set,获取检查结果
for (ConstraintViolation<Object> valet : set) {
String message = valet.getMessage();
if (StringUtils.isNotBlank(message)) {
if (message.startsWith("{") && message.endsWith("}")) {
message = message.substring(1, message.length() - 1);
}
validMessage = validMessage + I18nMessageUtil.getMessage(message, message) + ";";
}
}
} catch (Exception e) {
LogUtil.errorLog(log, () -> LogTextHolder.instance("serviceValid error", e));
throw new Exception("serviceValid error:" + e.getMessage());
}
if (!StringUtils.isEmpty(validMessage)) {
throw new Exception(validMessage);
}
}
@Bean("hibernateValidator")
public Validator validator() {
return Validation
.byProvider(HibernateValidator.class)
.configure()
.failFast(false)
.buildValidatorFactory()
.getValidator();
}
private static final Validator VALIDATOR = SpringContextUtil.getBean("hibernateValidator"); //(3)从火焰图的方法调用中可以看出(1)处的方法占serviceValid方法整体CPU的40%,(2)处的方法占55%
(1)处的buildValidatorFactory用于获取ValidatorFactory工厂对象,然后通过工厂生成Validator。(2)处则是使用创建的validator对象进行bean的合法化校验,若校验不通过则返回异常字段的集合。
ValidatorFactory的创建是一个非常消耗资源的过程,且该场景中主要配置为failFast为false,无其他特殊的配置,则ValidatorFactory是可以重用的。同时由于Validator对象内部会缓存已经校验过的Bean的元素据信息,则Validator对象也应该被重用。
通过将validator对象交由Spring管理生命周期,ValidatorFactory、Validator对象均可以保持其唯一性和重用性,如(3)处的代码所示。然后将(1)处替换成(4)处的写法即可。最终该方法消耗CPU从30% 降低到了不到0.5%。
Spring 参数配置缺失
public static <T> T getProperty(String key, T defaultValue) {
if (!StringUtils.isBlank(key)) {
if (null == environment) {
environment = (Environment)SpringContextUtil.getBean(Environment.class);
if (null == environment) {
log.error(">>> PropertiesObtainUtil#environment 没有初始化,请初始化后再使用");
return defaultValue;
}
}
String value = environment.getProperty(key);
if (null != value) {
try {
if (defaultValue instanceof String) {
return value;
}
if (defaultValue instanceof Integer) {
return Integer.parseInt(value);
}
if (defaultValue instanceof Long) {
return Long.parseLong(value);
}
if (defaultValue instanceof Float) {
return Float.parseFloat(value);
}
if (defaultValue instanceof Boolean) {
return Boolean.parseBoolean(value);
}
} catch (Exception var4) {
log.error("配置[{}]对应的值类型转换失败:{}", new Object[]{key, value, var4});
}
}
}
return defaultValue;
}在火焰图中搜索PropertiesObtainUtil.getProperty发现整体CPU消耗在11%左右,该方法如上所示,且主要的消耗来自于框架中的org/springframework/core/env/AbstractEnvironment.getProperty方法调用。
由于在压测环境缺少了一个Inteceptor相关参数的配置,导致在被该Interceptro拦截的所有方法调用都会消耗一部分CPU资源来让Spring遍历所有可能有参数配置的地方来获取该参数,最终导致CPU资源的浪费。添加对应参数的配置后,CPU消耗从11%降低至1.5%
压测框架
内部压测框架由于需要对压测数据进行控制,防止其污染生产数据,平台通过Agent的方式对代码中的部分方法的调用配置了采样,如线程池数据、HTTP请求参数、Kafka消费等。这部分采样消耗在代码中无法体现,但是在火焰图中显示仍然整体消耗了6%左右的CPU。
经与平台沟通,该部分CPU无法优化,但生产环境不会有该部分资源消耗。
后记
借助火焰图工具,可以帮助我们发现一些在编码过程中容易被忽略,且在非压测场景下也无法体现出性能问题的代码。然而这些逻辑可能会在流量突增的时候成为系统宕机的导火索。同时火焰图还可以针对其他的指标进行采样,可以在内存分析、卡顿分析等场景为我们提供助力。